Lada
LXC container
Media links
A sizeable kind of content made available is video. Instead of implementing or outsourcing an in-browser video player, vlc is used with its ability to stream video over HTTP. To redirect to vlc, links are starting with a custom scheme but then follow mostly HTTP URL formats. Some more functionality is achieved through a few urlparams and any unrecognized urlparams are forwarded to vlc for fetching the webserver:
<a href="vlc://lada.tizarne.com/videos?next=999">click me</a>On a resolve, the browser will pass the url to the vlc urlhandler and the urlhandler will call:
$ vlc 'http://lada.tizarne.com/videos?next=999'Some urlparameters though are translated to vlc options and will not be present in the URL fetched by vlc. These include:
titlefor displaying instead of the filenameaudiolanguagefor switching from the default track 0, it is a string like 'eng' or 'fre' because the video files also encode the language in the track metadatatas a start time, mainly used by Lada#Cards.rateas the playback speed rate, a float value like 1.1 or 1.5 (default obviously 1.0)
Playlists
To play a list of items, a .m3u file is generated (somewhere else) on the webserver, which then allows vlc to play multiple items from a single url. See /dlw.php for and example the .m3u generation mechanism.
The vlc specific extended .m3u specification also allows Lada#sponsorblock.php to generate segments of a video to skip with the following:
#EXTVLCOPT:start-time=31.771
#EXTVLCOPT:stop-time=2285
http://{servername}/{path/to/video.mkv}
#EXTVLCOPT:start-time=2568.65
http://{servername}/{path/to/same/video.mkv}Setup
A step-by step guide to configure the browser and OS to resolve VLC urls is available under /setuplinks.php.
Webserver contents
Video
Scripts in php display youtube, videos (TV series), movies, dlw and more. Video files are usually directly served but the php scripts always link to them as vlc://[lada https domain]/path/to/movie.mkv to be handled on the client-side browser in a specific way, for example opening vlc and streaming the https file over the network directly 'on-screen'.
Youtube
A forced-php script under /youtube, displays downloaded youtube videos and their thumbnails arranged by channel, by playlist, alone or by other criteria. Reads data about the videos, channels and playlists from dbname=videos but also integrates sponsorblock by checking existence in #RAMdb and then rewiting the link as /sponsorblock.php?params.... Any sponsorblock-present video will then have a class="sponsor" and the /style/youtube.css shows a blue border around it.
Detailed video
Videos also have a detailed page where their description is available, that is slightly HTML enhanced to transform plaintext links to clickable <a> elements, and to parse youtube.com and youtu.be links to check existence local videos. In the case another local video is referenced by the description of a first one, its link is replaced by a local link and the link gets a class="selected" which highlights it white instead of gray. A t url parameter can control the start time, in case only part of the video is meant to be referenced.
Cards
After the description, a list of all youtube cards and end panels is shown. This data is stored in the cards and cards_ranges tables, and it is fetched "manually". The main download tool yt-dlp does not support cards and because of that it just downloads the youtube.com/video?v={id} to .html and parses the relevant bits of javascript from there and inserts those to database. This is a very unstable method and will break any time the js' json key names change or the data is moved to somewhere else than the landing html of the video.
Main data elements are a text description and link, present in some form for all cards. Then, a start and end time are optional. Also, the link is internally sanitized because it actually has a youtube.com/redirect?url=<base64(url)> tracking system. The link may also go to a youtube resource: videos, channels and playlists are recognized and instead of a youtube.com link, it uses the local version (if it is present in the archive).
Hires videos
Videos that are available in width>=1080 && height>=1080 are also downloaded in a smaller .1080p.mkv version, see Perun#/home/user/yt.py. In the database, they are present in the table altvideos and this script displays such videos by making the main medialink go to the .1080p version and adding a second {resolution} link to the fullres version, which is usually 4K but may be one of the less conventional 2540x1440, 2880x5120 or 3840x1080.
Playlists and more
Playlists have medialinks at the top that allow playing the entire playlist, also in different sorting modes.
In the database there are so-called metaplaylists that are a quite fancy undocumented tangle of php. Those are shown as playlists but are generated by the php instead of being statically stored. This allows for functionnality like :
- super-playlists (a PL-music that is a parent to PL-ina-edith-piaf AND PL-ina-france-gall AND PL-music-clips).
- direct sql filters, like
SELECT * FROM videos WHERE length(id)!=11;for the PL-tv (== any non-youtue videos are in PL-tv: quite useful). - some more, the php code is the only documentation at this stage.
TV series
/videos is a forced-php script that tracks watching progress in the database under dbname=videos. It displays all series on the landing page and makes a "watch next" vlc:// link available for each series. Some series that do not have ordered seasons will not have a global natch-next link, but on opening the series all seasons are shown and thos will have "watch next" links if the episodes are ordered. Unordered episodes means that in a season all episodes displayed have a green tick in the upper right corner if they have been watched. The entire script is server-side only and does not use javascript. It also features language track selection support by passing the ?audiolanguage={lang} URL parameter in the vlc:// links and title specification through the URL parameter &title={urlencode(title)} to be displayed in vlc. The vlc opening script also needs to carefully parse URL parameters and only take those that refer to it, like audiolanguage and title. This is because the next, next_season and watch URL parameters specify the mechanism to count episode progress. This takes place when vlc fetches the URL: it will be to the /videos script itself with some $_GET parameters. This script will then update the database accordingly and only after that set the HTTP header 302 redirect to point to the video file for vlc to start playing. This also allows for vlc to play the next track whenever the user presses "next", because the vlc playlist has only one item, it will just refetch the same url. But because the php script has previously updated the database, it will again update the watching progress, and then redirect to the next video file in the sequence.
Movies
A forced-php script under /movies, displays locally stored movies in a browseable thumbnail format. The idea is to select one for viewing and then vlc:// stream it. It supports tagging funcitonality, where movies can be shown filtered by a specific tag (i.e. only ghibli movies). Then those tags can be edited in two ways directly through the website:
- For each movie specifically, the right corner shows a list of all tags and highlights the enabled tags for that movie. Simply clicking a tag will toggle its enabled/disabled state for that movie
- In the "edit tags" page, upon selecting which tag to edit, all movies show up as small thumbnails and a green border shows an enabled movie. Changes can be made exaclty like with checkboxes to toggle on or off selected movies and the submit button saves the changes. A new tag can be created just by changing the urlparam
tagbefore submitting.
Map
Shows a scrollable and zoomable worldmap, in different layers too. /leaflet.html handles display of the maps from raster tiles and manages all the layers. It uses the leaflet javascript library, which is statically available in /leaflet/.
What are Tiles
Tiles are square pictures available on URLs in the format /maps/{layername}/{z}/{x}/{y}.png. Each layer is a set of tiles that show the world as a square at different zomm (z=0..20) levels. At zoom 0, the world fits in a single tile at /maps/{layername}/0/0/0.png. But every zoom+1, the size doubles and four times more tiles are needed: /1/0/0, /1/0/1, /1/1/0, /1/1/1 are all the tiles at zoom=1. At zoom 20, a tile depicts an area of about 20x20m at 45°lat (keep in mind a coordinate reprojection sphere surface->square is needed).
Where are Tiles
Map layers have their data stored in a database in Osm, because storing all the actual tiles is impossible. The tiles are then rendered on request by Osm#Tirex and available as files under the corresponding urls. For zooms 0 to around 13, rendering needs to process a lot of data, which makes the rendering of those tiles take more than a few seconds per tile: they need to be cached instead of forcing the user to wait mutiple seconds at every pan of the map. Up to z=11, they take up about 30GB or 350'000 files (tiles are stored as 8x8 metatiles, so there are about 64x more: 22.5 million tiles).
Static Tiles
Static raster tiles are directly mounted in the webserver, this is the case for one layer, /satellite/{z}/{x}/{y}.jpg. As mentioned above, storing all the tiles for any layer is impossible, so here only the upper zoom layers (z=0 to 10 is currently entirely available) are stored, and every time a tile is missing, it is replaced by ocean. This makes sense for the actual ocean which makes up 70% of the surface, but at lower zooms in land, there just is no data.
Fallback static Tiles
Another somewhat-solution to that a fallback-enabled layer: this needs /leaflet.tilelayer.fallback.js[1] , and is currently used for the /satellite/ layer as "satellite with fallback". Instead of displaying the error tile whenever a specific tile is missing (/satellite/ocean.jpg for /satellite/), it reuses upper-zoom tiles and pixellates them.
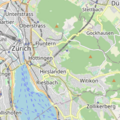
plain map generated by renderd, /osm/plain/12/2145/1434.png

satellite imagery from ©MapTiler /satellite/12/2145/1434.png
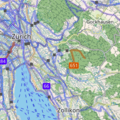
cycling map, /osm/cyclosm/12/2145/1434.png



The url has javascript that self-updates lat, lon, layer, overlayer, and zoom urlparams to allow for refreshes and saving current view of the map. This also enables navigating to explicit lat/lon coordinates.
Text bubble
On a click on the map, a text bubble appears for that specific point with exact lat/lon coordinates and some other useful info. The javascript also computes the specific tile file in {z}/{x}/{y}.png coordinates and supports links that navigate/resolve to a specific location with the tile_coords={z}/{x}/{y} urlparam, instead of lat/lon. The mathematics of these two conversions (lat+lon ⇔ tile_coords [+zoom]) are simply copy-pasted implementations from wikipedia (see leaflet.js file comment for the exact link).
Search features
A search funciton is available through the search bar. It queries the nominatim local installation and on the click of a result, also draws the administrative outline of it on the map. Address searching works as long as the text in the query approximately matches {street} {number}, {village/city}, {optional:district}, {optional:region}, {optional:country}.
See Nominatim for the backend.
Uploadable storage
/ram.php shows downloadeable files and provides an uploading form, /ramulpoad.php handes the form and writes uploaded files to /var/www/html/data/ram/{filename}. Under /var/www/html/data/ram/ there is a tmpfs RAM filesystem mounted, to allow volatile operations, and therefore erasure across server reboots (volatility is a feature in this case).
Kiwix
A local kiwix server for wikipedias, wiktionaries, stack overflow and other sites in multiple languages. It is slightly modified to add the following snippet
<script type="text/javascript" src="./inject_javascript.js"></script>to every html article (more precisely, in viewer.html). It also serves inject_javascript.js which:
- builds a Lada#Interlanguage_links url to interlanguage versions. It then adds a button to that in the UI navbar. If clicked, it opens a new tab with a list of links to the same page in all other languages, linking to the local kiwix in other languages if they are available (else the links go to the internet).
- changes all local links in the displayed page to allow for more convenient right-click-open-in-a-new-tab-navigation. Such horizontal browsing (opening multiple browser tabs) only shows the
content.htmlpage, which does not have the navbar. Injecting those changes means a navbar now shows in a new tab. Instead, because the UI is structured with an iframe, clicking aviewer.htmlurl in aviewer.html's iframe can do a double weird thing. This needs to be checked and redirected but it now works.
The serving of a custom resource is controlled by a mapfile and the env variable KIWIX_SERVE_CUSTOMIZED_RESOURCES, which is an undocumented feature but the source code is somewhat deciferable.
On the other hand, the viewer.html template is compiled into the libkiwix library directly. Editing this file did the trick, but it also involved recompiling libzim and kiwix-tools(which contains kiwix-serve the server exec) because the debian packages are so old that they are not compatible with a newly compiled libkiwix.
Interlanguage links
The script /wikilangs.php allows to query the Lada#Wikilangs_database and display results as a list of links in other languages of the provided wikipedia or wiktionary page: either green coloured for locally available versions, or red coloured for externally available, on wikipedia.org and wiktionary.org.
This functionality is clumsy with the php script itself, only querying as urlparams is supported, but with different parameter sets:
title,lang,type: explicitly provide exacttitleand origin language.typeis eitherwiki(default) orwiktionary.wikipath: determinelangandtypefrom its dirname, and extract its basename as thetitle.
An frendlier interface is provided through a "laguages" button in the kiwix interface directly, see for Lada#Javascript_injection implementation and details.
Stats
Read monitoring and display it with Javascript library plotly. Plotly.js is statically loaded from the webserver to allow completely internet-less operation. The data is in json prepended with "{global_var_name}=" so that it is valid javascript and can be simply used in HTML:
<script src="/stats/{var_name}.latest.js"></script>The plotly library then shows an interactive graph that allows zooming, panning and exporting view to .png.
Currenly the following data traces can be displayed:
bandwidth.phpshows the last 24h of download and upload speed to the internet, in 5-minutely samples.bandwidth.php?mode=monthlythe per month download and upload usage, billing cycle the 10th of every month.ram.phpmain server RAM free space, displays entire weeklivebw.phpexplained below
livebw.php
A dynamic graph of the last one minute of internet upload and download usage. It uses an infinitely-fetching javascript XHR request, which serves a csv file of the data. Each line read is then parsed and added to the data. Plotly then supports a 'updated_data_redraw' function to refresh display.
This data is read from /proc/net/dev which contains a total count of bytes transferred and received over any net interface. It is loaded into a database table with timestamps at small intervals (microsecond scale). That data is then read by a python script that deduces and averages the instantaneous (rigourously, the milisecond-scale) data bandwidth rate. And it sends it through the webserver in the infinite csv file for displaying.
Arch and artix package mirror
Makes software/ dataset available, by design all static files allow for package mirror operations. Use
Server = https://lada.tizarne.com/artix/$repo/os/$archfor artix,
Server = https://lada.tizarne.com/archzfs/x86_64/for archzfs, and
Server = https://lada.tizarne.com/arch/$repo/os/$archfor arch in /etc/pacman.d/mirrorlist. To make the two directories available in the webserver root, symlinks are used :
arch -> data/software/arch
artix -> data/software/artixAudio
Feeds (RSS)
A forced-php script under /feeds, local podcast and radio recordings are served as RSS and data is read from dbname=audio. The audio files are assumed to be under /data/audio/podcasts/{db_audio:podcasts:directory}/{db_audio:episodes:filename}. Some extended content like images in podcast shownotes have been manually downloaded and are also available on the local webserver. To allow for flexibility in the data storage directory, the server name and the PHP script name, modified shownotes refer to images as
<img src="$SERVER/one.jpg"/>which the webserver then converts to :
<?php $dataroot='/data/audio/podcasts/'; ?>
<img src="<?=$_SERVER['REQUEST_SCHEME'].'://'.$_SERVER['HTTP_POST'].$dataroot.$podcast['directory']?>/one.jpg"/>Like this, any changes in $dataroot or servername do not require a database rescan-and-replace. A similar independence of data and implementation is also achieved with $SERVER in /youtube. For simplicity in the example, html de- and encoding are omitted. They are used in podcast shownotes whenever these are formatted as HTML because that inner HTML needs to be escaped to prevent interfering with the outer XML of the carrying document:
<description><h1>Title!<\h1><p>look at this image <img src="$SERVER/one.jpg"/></p></description>and resolving $SERVER:
<description><h1>Title!<\h1><p>look at this image <img src="http://{servername}/data/audio/podcasts/{pod_name}/one.jpg"/></p></description>Shownotes
Adding a urlparam /feeds?id={id}&show will make an HTML webpage instead of the RSS XML feed and display only the shownotes of all episodes (as unescaped HTML). This is useful for debugging of $SERVER usage or consulting podcast information as HTML.
Installation of webapp and its webserver, accessible under /music.
Piwigo
PHP picture gallery which is fully under /var/www/html/piwigo. It also uses a #mysql database to store all data (incompatible with postgres). The pictures themselves are accessed under /var/www/html/piwigo/galleries/ and a symlink goes to family -> '/mnt/family/photos et vidéos/'. Piwigo has strong requirements for file- and directory names, which are enforced if /mnt/family/photos et vidéos/sanitize_names.py is run. This includes:
- no spaces
- no diatrics (é,è,à,ô,š,ť,ü,ö,...)
- no symbols except - and _ (?,!,+,=,@,#,$,%,&,*,),(,...)
This script also checks proper permissions for the www-data user (who is not the owner).
Piwigo also generates thumbnails dynamically to a different location. To keep those pictures together and outside of the lada rootfs backup, there is a symlink into /mnt/family/.thumbnails where the thumbnails actually reside. But this becomes a problem when writing there because lada usually has readonly access to data. Also because the dataset source of truth is not on the server, this means writes have to be backpropagated. Lada therefore has a readwrite mountpoint /mnt/family_thumbnails to the subdirectory .thumbnails/. To back it up, this directory is rsync'ed to the source of truth dataset before every snapshot as part of the backup script.
Gitea
Go server for managing git repositories. But here it is used mainly to display archived repositories and allow browsing them in the browser like github, with syntax highlighting and markdown display. It is available under /gitea behind a reverse proxy. It uses the main postgresql database cluster and has the dbname=gitea for all its data. It runs through a systemd.service under the git user and manages repositories stored in /var/lib/gitea/data/gitea-repositories/. Because it expects to manage repositories instead of readonly displaying them, some workarounds are needed to add an archive repository:
- create a repository as the
archivesuser in the webinterface. - remove the corresponding
/var/lib/gitea/data/gitea-repositories/archives/{name}.gitdirectory (note any CamelCase names are converted to lowercase). - symlink to the actual repository, usually in
/mnt/software/git_cloned/{author}/{NaMe}while taking in account some upper/lowercase name conversions. - open the repository through the webinterface, it will give an
HTTP error 500but any subsequent refresh should display the repository.
Currently step 3 is automated in /var/lib/gitea/data/gitea-repositories/archives/mklinks.sh.
In there, any archlinux (AUR) repositories are prepended with aur_{name} for clarity.
Typing practice
A clone of https://www.how-to-type.com/typing-practice/quote/ where the javascript fetches a quote from the local infrstructure: a gutenberg library in kiwix. This is a working prototype, some things don't work consistently but the core functionality of being able to practice typing works.
The gutenberg library, when served by kiwix, has a /random url endpoint which is used here. Then, some chapter is randomly selected and its .innerText is somewhat sanitized against difficult to type characters and that is the quote to practise. There is no support for length of the quote or topic, except for selecting between fench or english gutenberg library (but only in source code, not by the user).
sponsorblock.php
Meant as a generic adapter to play videos and automatically block sponsor spots. It takes a few urlparams to determine the video file and its id. Then, it reads Lada#RAMdb and if any skip segments exsits, compiles them to a set of VLC playlist #VLC_opt_start={time} and #VLC_opt_stop={time} instructions. Those are then output as text, representing a playlist with the corresponding source video file. Clicking a sponsorblock.php link to play in vlc then seamlessly skips the detected sponsor spots. As an example vlc playlist file, fetching:
/sponsorblock.php?file=iihVxjJjY9Q.mkv&id=iihVxjJjY9Q&parent=UC8XjmAEDVZSCQjI150cb4QA&source=youtube&title=The+Story+We+Tell+Ourselves+%7C+Pilgrims+and+Thanksgivingwill respond with
#EXTM3U
#EXTVLCOPT:start-time=0
#EXTVLCOPT:stop-time=171.549
#EXTINF:60,iihVxjJjY9Q.mkv
https://[...]/data/youtube/UC8XjmAEDVZSCQjI150cb4QA/iihVxjJjY9Q.mkv
#EXTVLCOPT:start-time=176
#EXTVLCOPT:stop-time=171.549
#EXTINF:60,iihVxjJjY9Q.mkv
https://[...]/data/youtube/UC8XjmAEDVZSCQjI150cb4QA/iihVxjJjY9Q.mkv
[...]This is meant as a generic script but the caller still needs to correctly provide the video file path: This is specified by the urlparam source and only youtube and youtube_tmp are currently supported:
youtube->/data/youtube/{?parent}/{?file}youtube_tmp->/youtube_tmp/{?file}
Forced php scripts
For cosmetic reasons and url shortness, some php scripts do not have a .php extension. They are then manually forced to be php-interpreted in the server. This also allows to reference nonexisting subdirectories "under" the script: /youtube is forced-php, and then /youtube/video/{videoid} and /youtube/channel/{channelid} are valid urls (that are also in practical use). Apache2 server configuration in /etc/apache2/apache2.conf:
<FilesMatch "youtube$|redirect$|feeds$|movies$|dvd$|videos$">
ForceType application/x-httpd-php
SetHandler application/x-httpd-php
</FilesMatch>The FilesMatch section accepts regexes, so the a|b|c syntax allows a shorthand for repeated <File a>...</File><File b>...</File>... sections. This can become a security issue if the regex is edited to include wider syntax and more complicated regex parsing. A $ was added to force extension-less files only, as /style/youtube.css would have matched and been php-interpreted.
Databases
Normal postgresql database
Is started by systemd postgres service and keeps data in /pgsql/data/. Contains two dbnames videos and audio.
db videos
Biggest table is videos which contains all youtube videos and their descriptions which contribute most to the size. Tables playlists, channels and others provide all youtube functionality for three types of resources: videos, channels and playlists.
Also contains all videos data in tables series, seasons and episodes. They are only semi-automatically filled up, mostly through python. This happens through snippets in the history under /home/user/.python_history.
db audio
Contains data for #Feeds_(RSS) in two tables: episodes and podcasts. Most items actually are podcasts but some radio recordings are also present as podcasts and are available as RSS feeds.
Wikilangs database
This database contains data about all Wikipedia and Wiktionary pages inter languages: between en, fr, sk and de. Each page is also stored by text title to allow simple searching. It runs on port 5434.
Because it contains more data and reaches >10GB in size, and also to allow modularity; it is stored outside the root filesystem of lada, with the wikis dataset as a sub-dataset wikis/langs.
Data source
The data is directly downloaded from Wikipedia servers, specifically the pages.sql.gz and langlinks.sql.gz files. These are then imported into the database with some adjustments, like discarding most data columns:
pages: only keeptitle:varcharandid:bigint. Addlang:varcharfrom whichpages_en.sql.gzorpages_de.sql.gz, ... file it comeslangs: only keepid_from:bigint,id_to:bigintandlang_to:varchar. Addlang_from:varcharlike above.
The id:bigint columns are language dependent, so a unique id will not uniquely identify a page, only a tuple (id,lang) will.
RAMdb
Volatile database, keeps its data in /mnt/ramdb/ which also is a 2GB tmpfs RAMdisk. This database has a dbname sponsorblock and a table sponsorblock that holds sponsorTimes.csv data for database-access instead of forcing the weberver to read a 1GB .csv with php. The volatility though is mostly for backup purposes: to avoid redundancy. The source of truth for that data is from the internet, but locally it is the .csv. Because that file is located in /youtube, it is backed up. The database would then only be backed up for the schema. The sponsorblock table was in the normal database before, but it changes so fast that the about-biweekly backup of the entire container ballooned from about 2.5GB up to 16GB per snapshot, and 25+GB for multiple snapshots. Now only the /mnt/ramdb_init/ data is backed up, about 20MB and generally static.
/mnt/ramdb_init
Contains empty database instance for copying over to the tmpfs upon container boot. It is a database with the sponsorblock table and its indexes, just with 0 rows. The configuration also states that the running port is 5433 to prevent conflict with the normal database (on default port 5432). On startup, the ramdb systemd service starts /root/ramdb.sh which sets the entire RAM database up and populates it by running /home/user/addcsv.py as user in a second thread.
mysql
Used by #Piwigo because it doesn't support postgresql. Listens on localhost:3306.
External redirects
Main website entry point and reverse-proxy redirects some subdirectories to other webservers:
/giteatolocalhost:7000/for gitea/kiwixtolocalhost:8000/for kiwix/dewato[dewa]:8051//musictolocalhost:4533/, navidrome instance/getlivebwto websocket implementation, see #livebw.php/collaborafor nextcould-integrated libreoffice online suite, also uses some websockets
Some direct ports are externally forwarded:
80for http443for https8080for /dvd/ vlc playing as an almost-DVD experience
Javascript injection
To add some enhancements or features to the redirected webUI /dewa, there is a corresponding /dewa.html document that runs some bits of javascript in a parent window and then displays the actual webUI in a child (fullscreen) iframe. It's quite simple and just fills in the password + clicks the login button automatically. This is also easy because all the UI is on one page.
These features are by default impossible to do (JS manipulate contents of an iframe), but only because both the parent document and the iframe are from the same origin webserver, the browser allows it.